

Quality-based Ranking for Queries with Commercial Intent
 наш канал в
наш канал в  ЯНДЕКС.ДЗЕН.
ЯНДЕКС.ДЗЕН.
1. ВВЕДЕНИЕ
В некоторых задачах информационного поиска единственной целью поисковой системы является лишь поиск самого релевантного документа по заданному запросу. В случае, когда множество релевантных документов мало, это похоже лучший ответ на нужды пользователя. Однако в настоящее время есть множество групп пользовательских запросов, на которые поисковая система может дать большое кол-во высокорелевантных ответов. В отличие от поиска единственного правильного ответа, такие запросы включают множество возможных ответов, из которых можно выбирать.
В эти группы запросов, в частности, входят коммерческие запросы, когда пользователи часто хотят выбрать лучшее предложение из многих похожих друг на друга.
Коммерческие запросы формируют очень высокую конкурентную среду, в которой повышение позиции сайта в результатах поиска означает рост доходов сайта. По этой причине коммерческие сайты прилагают все усилия, чтобы занять место в топе результатов выдачи, таким образом, увеличить свою прибыль. Веб-мастера оптимизируют текстовый контент и покупают входящие ссылки, чтобы облегчить поисковой системе поиск и представление сайта пользователям в ответ на коммерческие запросы. В результате, с точки зрения текстовой релевантности и основываясь на мере качества ссылок, коммерческие сайты в топ-10 являются часто одинаково релевантными.
Кроме того, с точки зрения пользователей (а не поисковой системы), вероятно, наибольшую релевантность получат наиболее конкурирующие сайты, поскольку инструкции по оценке направленны, прежде всего, на оценку тематической релевантности документа.
Таким образом, любое изменение в позициях сайтов в топ-10 результатов поиска не приведет к изменениям метрики качества ранжирования.
Однако, бросая все силы на оптимизацию сайтов, многие веб-мастера забывают об улучшении сайта для пользователей[13]. Поэтому удовлетворенность пользователей для разных коммерческих сайтов может значительно отличаться. В частности, дизайн, наличие онлайн-форм обратной связи, отзывы пользователей на предлагаемую продукцию значительным образом влияют на отношение пользователей.
Данные наблюдения предполагают, что использование информации о качестве сайтов при ранжировании коммерческих запросов, при условии выдачи множества высокорелевантных ответов, может значительно улучшить ранжирование и увеличить удовлетворенность пользователей. Качество документа по коммерческому запросу, при условии, что документ тематически релевантен, называют коммерческой релевантностью.
Существуют исследования, в которых авторы предлагают подходы к оценке качества сайта и его интеграцию в алгоритм ранжирования. Например, критерии качества веб-страницы с точки зрения поведения пользователя были описаны во многих статьях [1, 2, 11]. Формальные критерии, которые описывают удобство использования, степень доверия, дизайн, и т.д., должны быть построены на основе важности определенных аспектов качества сайта для пользователей. Такие критерии могут включать длину текста, грамотность содержания, читаемость заголовка страницы, наличие карт, информацию о компании, легко запоминающиеся номера телефонов, бесплатную доставку [7].
Существуют некоторые работы, которые предлагают подходы к использованию дополнительной информации о качестве сайта при ранжировании [3]. Например, объединение оценок из нескольких источников, таких как оценки асессоров и данные о кликах [14] или текстовая релевантность и дата публикации [6].
В нашей работе мы предлагаем новый подход к качественному ранжированию, которое включает развитие новых аспектов релевантности и внедрение многих факторов, характеризующих качество веб-страницы по предложенным направлениям. На основе нескольких факторов качества мы формируем совокупный рейтинг, который назвали коммерческой релевантностью. В отличие от [14] мы экстраполируем оценку коммерческой релевантности ко всему обучающему множеству.
Для тематически релевантных результатов поиска мы определяем суммарное значение релевантности как взвешенную сумму тематического и коммерческого значений релевантности. Наш подход позволяет значительно улучшить оффлайн и онлайн метрики, по сравнению с «дефолтным» алгоритмом ранжирования.
Остальная часть этой статьи построена следующим образом: в Разделе 2 мы демонстрируем новую шкалу релевантности, которая помогает нам оценивать качество коммерческих сайтов. Раздел 3 посвящен нашему методу обучения, с учетом дополнительной метрики качества документа. В Разделе 4 мы описываем новые факторы ранжирования, которые используются для определения коммерческой релевантности. В Разделе 5 описаны новые метрики для оценки метода. И, наконец, в Разделе 6 обсуждаются наши результаты и планы на будущее.
2. ШКАЛА КОММЕРЧЕСКОЙ РЕЛЕВАНТНОСТИ
Для проведения оценки качества сайта по запросам с коммерческим интентом можно взять за основу оценки асессоров или кликовые данные [9]. Мы решили использовать оценки асессоров, так как они дают менее искаженные данные, по сравнению с кликовыми или тулбарными данными [14].
Используя кликовые или тулбарные данные, очень трудно определить, удовлетворен ли пользователь результатом поиска. Пользовательское поведение по запросам с коммерческим интентом может значительно зависеть от категории продукта, его цены, и т.д. (сравните доставку пиццы и покупку линзы цифрового фотоаппарата). С другой стороны, кликовые и тулбарные данные могут дать некоторую полезную информацию, поэтому мы сделали эти данные доступными для асессоров во время оценивания.
В случае неделимой оценки качества, разные асессоры могут обратить внимание на различные аспекты качества. Кто-то, вероятно, знает сайт и то, что ему можно доверять, несмотря на уродливый дизайн и неудобство использования. Другой асессор обратит особое внимание на присутствие отзывов пользователей и так далее. В целях лучшей формализации процесса оценки мы разделили меру качества сайта на несколько компонентов. В то же время это обеспечивает лучший охват особенностей сайта асессорами.
Основываясь на данных множества исследований [5, 11, 12], мы определили расширенный список аспектов коммерческой релевантности. Затем, для облегчения процесса оценки, мы выбрали четыре характеристики качества, которые, как нам кажется, охватывают большую часть независимой информации о качестве. Это означает, что качество сайта, определенное этими характеристиками, охватывает множество особенностей сайта. Вот перечень отобранных качественных характеристик сайта: надежность (степень доверия к сайту), удобство использования, качество дизайна и качество сервиса.
Мы разработали детальные инструкции по оценке качества сайта для асессоров. Согласно этим инструкциям, оценка состоит из двух стадий. На первой, эксперт должен определить, релевантен ли документ данному запросу. Мы используем широко распространенную шкалу определения актуальной релевантности с 5 уровнями градации, в которые входят нерелевантные, релевантные, очень релевантные, полезные и витальные оценки.
Оценка качества сайта – намного более сложный процесс, отнимающий больше времени, чем оценка тематической релевантности (и особенно анализ кликовых данных). Частично это компенсируется тем фактом, что в нашем методе оценки качество должно оцениваться только для релевантных документов.
Мы не рассматриваем документы с полезными или витальными оценками, предполагая, что они часто являются единственной целью поиска по указанному запросу. Как говорилось ранее, мы сосредотачиваемся только на запросах, которые включают выбор между одинаково подходящими результатами.
На первой стадии оценки также оценивается разнообразие продуктов и услуг, предоставляемых документом по данному коммерческому запросу. Мы различаем три степени разнообразия ассортимента: маленький, стандартный и большой. Числовая оценка разнообразия ассортимента по запросу q и документу d обозначена V (q, d).
В течение второй стадии оценки определяются надежность, удобство использования, качество дизайна и качество сервиса для всего сайта. У надежности (степени доверия) и качества сервиса имеется четыре степени по нашей шкале: спам, нормальный, хороший и отличный.
Сайт будет отмечен как «спам», если он не будет давать возможность совершить заказ или получить желаемую услугу (являться фейковым сайтом). Сайты с оценкой «нормальный» не являются плохими, но и не отличаются от тысяч подобных коммерческих сайтов. «Хорошие» сайты предоставляют пользователям стандартный набор услуг и, наконец, «отличные» сайты – это хорошо известные сайты ведущих компаний. Надежность (степень доверия) и качество сервиса к указанному сайту «s» обозначены «T(s)» и «S(s)» соответственно. Обратите внимание на то, что эти показатели не зависят от определенной пары запросов «q» и документа «d».
У характеристик удобства использования и качества дизайна есть только три степени качества: плохой, хороший и отличный. Показатель этих коммерческих аспектов релевантности обозначен «U(s)» для удобства использования и «D(s)» для качества дизайна. Величина всех вышеупомянутых показателей от 0 до 1.
Для будущего использования информации о качестве во время обучения, мы объединили оценки четырех параметров в единый показатель коммерческий релевантности. Конкретнее, мы использовали следующую формулу:
Rc (q, d, s) = V (q, d) • (2T (s) + U (s) + D (s) + 2S (s)), (1)
где Rc (q, d, s) значение коммерческой релевантности документа «d» по запросу «q» для сайта «s».
Значимость параметров надежности (степени доверия) и качества сервиса – вдвое больше, чем у остальных параметров. Это сделано по той причине, что на наш взгляд, эти свойства более важны с точки зрения удовлетворенности пользователей; но мы не рассматриваем этот выбор параметров как единственно возможный.
3. ОБУЧЕНИЕ С НОВЫМИ ОЦЕНКАМИ
Оценка коммерческой релевантности – очень трудная задача, поэтому в условиях ограниченного бюджета количество оценок коммерческой релевантности будет намного меньше, чем количество оценок тематической релевантности. Мы не можем отказаться от тех оценок тематической релевантности, у которых нет соответствующих значений коммерческой релевантности. Это может привести к значительному сокращению размера обучающего множества и, как следствие, к ухудшению качества формулы ранжирования.
Таким образом, прежде чем начать процесс получения информации о рейтинге, мы должны экстраполировать оценку коммерческой релевантности на все обучающее множество. Это процедура экстраполяции состоит из двух шагов. Во-первых, мы обучаем функцию ранжирования на небольшом множестве, которое содержит оценки только коммерческой релевантности. Полученная формула ранжирования дает нам оцененное значение коммерческой релевантности Rc (q, d, s), которое обозначено Rcest (q ,d, s).
После этого мы применяем формулу ранжирования из первого шага к полному обучающему множеству с оценками тематической релевантности. Это является возможным, потому что мы используем один и тот же набор факторов для обоих обучающих множеств. Так как только высоко релевантные документы получат оценку коммерческой релевантности, определение этих оценок также вычисляется только для пар «документ-запрос», обладающих наиболее релевантными оценками по шкале тематической релевантности. Другие пары «документ-запрос» из обучающего множества получат нулевой показатель коммерческий релевантности.
Обладая значениями показателей коммерческой релевантности для всех тематически релевантных результатов по запросам с коммерческим интентом в нашем обучающем множестве, мы можем вычислить показатель объединенной релевантности:
Ru(q, d, s) = Rf (q, d) + α • Rcest (q ,d, s), (2)
где Rf (q, d) тематическая релевантности, Ru (q, d, s) суммарная релевантность и «α» – это весовой коэффициент.
Используя полученный суммарный показатель релевантности, мы обучаем формулу ранжирования по всему массиву данных. Коэффициент весомости «α» определяется эмпирически таким способом, чтобы он, с одной стороны, максимально повышал вклад коммерческой релевантности, а с другой стороны, не в ущерб метрикам тематической релевантности. В итоге мы получаем формулу ранжирования, которая вычисляет суммарную релевантность, в которую, в свою очередь, включены показатели тематической и коммерческой релевантности.
4. ОСОБЕННОСТИ ИЗМЕРЕНИЯ КАЧЕСТВА САЙТА
Для лучшего расчета оценок новой релевантности, которые включают тематическую и коммерческую релевантность, мы вводим некоторые новые параметры, определенные для коммерческих сайтов. Они являются новыми в том смысле, что они почти бесполезны для определения рейтинга с точки зрения тематической релевантности, потому что оценки тематической релевантности не несут информации о коммерческом качестве. Но для приблизительного расчета новой коммерческой релевантности эти особенности очень полезны, так как они охватывают информацию о качестве веб-страницы.
Из многочисленных исследований по этой теме [3, 11, 12] мы выбрали некоторые многообещающие особенности и затем совместили их с нашими собственными разработками. В Таблице 1 приведен список некоторых особенностей качества, использованных в нашем исследовании. Обратите внимание на то, что большинство этих параметров являются доменными фичами, агрегирующими информацию из всех документов коммерческого сайта. Это подтверждается тем фактом, что, согласно Формуле 1, коммерческая релевантность зависит от качества всего сайта.
Список 1: Особенности измерения качества сайта.
- Подробная контактная информация
- Страницы компании в социальных сетях
- Отсутствие рекламы
- Количество различной продукции
- Детальность описания продукции
- Наличие службы доставки
- Наличие сервис-менеджера (электронная почта, телефон, обратная связь с клиентами)
- Консультационная система в режиме онлайн
- Ценовые скидки
- Читаемость доменного имени
- Средняя длина URL
- Средняя длина названия страницы
- Логичность названия страницы и содержания страницы
- Средняя глубина пути URL
5. НОВЫЕ МЕТРИКИ ДЛЯ ОЦЕНКИ МЕТОДА
Для оценки наших результатов мы разработали две метрики, подобные NDCG [8] и основанные на оценках асессоров о качестве коммерческих сайтов. Первая метрика представляет взвешенное значение качества результатов поиска для заданного множества коммерческих запросов. Его значение для одного запроса «q» выражается как:
Goodness (q) = | 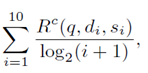 |
где Rc(q, di, si) – коммерческая релевантность для «i» результата поиска по запросу «q». Суммарное значение этой метрики для данного набора запросов является усредненным значением Goodness (q) всех запросов в этом множестве. Чем больше эта метрика, тем лучше результаты поисковой системы.
Наша вторая офф-лайн метрика представляет соотношение низкокачественных результатов поисковой системы для коммерческих запросов. Подобно первой метрике, это соотношение вычислено для данного множества запросов как усредненное число зависимых от запроса значений среди всего множества. Формула для значения, зависимого от запроса, выглядит так:
Badness (q) = | 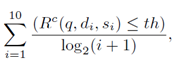 |
где «th» – порог минимального приемлемого коммерческого значения релевантности для результатов поисковой системы. Чем меньше эта метрика, тем лучше результаты поисковой системы.
Также мы используем известное A/B тестирование [10] и чередующиеся [4] онлайн эксперименты для оценки наших результатов. Мы обращаем особое внимание на метрики показатели отказов и кликам по запросу, вычисляемые только для кликов с длительным временем жизни. Мы полагаем, что эти метрики являются самыми ценными для запросов с коммерческим намерением.
6. РЕЗУЛЬТАТЫ И ОБСУЖДЕНИЯ
Мы предложили новый параметр качества документа для коммерческих запросов – коммерческую релевантность. Мы разработали несколько фич ранжирования для измерения качества сайта. В отличие от [14], мы предложили метод экстраполирования дополнительных меток релевантности для всего массива данных при получении информации о рейтинге, что позволило нам не терять информацию о тематической релевантности во время обучения.
Мы разработали оффлайновые метрики, подобные DCG, и наблюдали за их изменениями во время эксперимента с внедрением информации о качестве в формулу ранжирования. График 1 показывает изменение нашей метрики Goodness в течение некоторого времени до и после модификации формулы ранжирования.
Горизонтальная ось отражает параметр времени, вертикальная ось отражает относительный параметр нашей метрики.
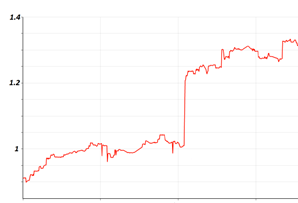
График 1: Увеличение метрики Goodness во время эксперимента
Как видно, эта метрика увеличилась почти на 30%, по сравнению с начальным состоянием. График 2 отражает изменение нашей второй оффлайновой метрики (Badness результатов поисковой системы). Снова горизонтальная ось отражает параметр времени, вертикальная ось отражает относительный параметр нашей метрики.
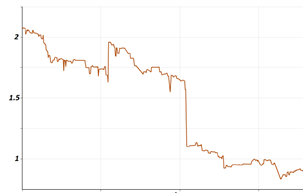
График 2: Уменьшение метрики негодности во время эксперимента
Как видим, метрика негодности уменьшается почти на 70%. В то же время расчет классических метрик NDCG с использованием только актуальных меток релевантности остался почти неизменным во время эксперимента.
Мы сравнили наши результаты с обучением без учета новых коммерческих параметров. Мы заметили, что улучшение метрик Goodness и Badness было почти на 20% меньшим, чем в случае, где были использованы все новые формулы.
Наш эксперимент чередования онлайн показал, что пользователи выбирали новые результаты ранжирования на 1% чаще, чем результаты системы определения рейтинга по умолчанию. В эксперименте A/B подход к определению рейтинга с учетом качества продемонстрировал 5% уменьшение в метрике показатель отказов, а метрика кликов по запросу увеличилась на 1,5%.
Будущие исследования включают использование в процессе обучения ряда оценок релевантности вместо единственной суммарной оценки. Другой подход к дальнейшему совершенствованию качества коммерческого поиска заключается в развитии новых коммерческих признаков сайта.
7. БЛАГОДАРНОСТИ
Авторы благодарят Павла Сердюкова за проведенные ценные обсуждения.
8. СПИСОК ЛИТЕРАТУРЫ
[1] A. B. Albuquerque and A. D. Belchior. E-commerce websites: a qualitative evaluation. In WWW 2002 Poster Session, May 2002.
[2] P. Alpar. Satisfaction with a web site. Electronic Business Engineering, 4, 1999.
[3] M. Bendersky,W. B. Croft, and Y. Diao. Quality-biased ranking of web documents. WSDM, February 2011.
[4] O. Chapelle, T. Joachims, F. Radlinski, and Y. Yue. Large-scale validation and analysis of interleaved search evaluation. ACM Transactions on Information Systems, 30(1), February 2012.
[5] V. Davidaviciene and J. Tolvaisas. Measuring quality of e-commerce web sites: Case of lithuania. Ekonomika ir Vadyba, 16, 2011.
[6] A. Dong and R. Z. et al. Time is of the essence: Improving recency ranking using twitter data. In WWW 2010 Proceedings, pages 331–340, April 2010.
[7] M. Ivory, R. Sinha, and M. Hearst. Empirically validated web page design metrics. In ACM CHI, April 2001.
[8] K. Jarvelin and J. Kekalainen. Cumulated gain-based evaluation of ir techniques. ACM ransactions on Information Systems, 20:422–446, 2002.
[9] T. Joachims. Optimizing search engines using clickthrough data. In SIGKDD’02 Proceedings, 2002.
[10] R. Kohavi, R. Longbotham, D. Sommerfield, and R. M. Henne. Controlled experiments on the web: Survey and practical guide. Data Mining and Knowledge Discovery, 18:140–181, 2009.
[11] G. L. Lohse and P. Spiller. Quantifying the effect of user interface design features on cyberstore traffic and sales. In CHI 98 Conference Proceedings, pages 211–218, 1998.
[12] M. J. Metzger. Making sense of credibility on the web: Models for evaluating online information and recommendations for future research. Journal of the American Society for Information Science and Technology, 58(13):2078–2091, 2007.
[13] K. Nikolaev, E. Zudina, and A. Gorshkov. Combining anchor text categorization and graph nalysis for paid link detection. In WWW 2009 Poster Session, April 2009.
[14] K. Svore, M. Volkovs, and C. Burges. Learning to rank with multiple objective functions. In WWW 2011 Proceedings, pages 367–376, March 2011.
По материалам: http://www2013.org/companion/p1145.pdf

Вы дочитали статью! Отличная работа!
- В некоторых нюансах продвижения сайтов сложно разобраться без опыта. Вы можете доверить продвижение вашего сайта нам. Отправьте заявку и мы изучим ваш сайт и предложим эффективную стратегию продвижения вашего бизнеса в сети.
- Подпишитесь на нашу рассылку - ежемесячно мы публикуем статьи про SEO-продвижение, онлайн-маркетинг, контекстную рекламу, новости отрасли и многое другое.
- Понравилась статья? Поделитесь ссылкой на статью в социальных сетях - возможно, статья окажется полезной для ваших друзей и коллег.
- Хотите стать экспертом?
Предлагаем вам почитать другие наши статьи, вот некоторые из них:
- Ищете работу? Приглашаем вас в наш дружный и профессиональный коллектив: интересные задачи, перспективы профессионального и личностного роста, одна из самых опытных команд в области SEO-продвижения в Санкт-Петербурге. Наши вакансии.






